7. brain_1.3M_integration#
Author: Haihui Zhang Copyright: scbiot
This notebook was modified from [here] (https://rapids-singlecell.readthedocs.io/en/latest/notebooks/demo_gpu-seuratv3-brain-1M.html) with rapids-singlecell
Setup#
Import GPU/CPU dependencies and configure runtime settings.
import scanpy as sc
import anndata as ad
import cupy as cp
import numpy as np
import time
import os
from pathlib import Path
import rapids_singlecell as rsc
import scbiot as scb
import gc
import warnings
warnings.filterwarnings("ignore")
dir = Path(os.environ.get("SCBIOT_EXAMPLES_PATH", Path.cwd()))
print(dir)
sc.logging.print_header()
/home/figo/software/python_libs/scbiot/.venv/lib/python3.12/site-packages/scanpy/_utils/__init__.py:33: FutureWarning: `__version__` is deprecated, use `importlib.metadata.version('anndata')` instead.
from anndata import __version__ as anndata_version
/home/figo/software/python_libs/scbiot/.venv/lib/python3.12/site-packages/scanpy/__init__.py:24: FutureWarning: `__version__` is deprecated, use `importlib.metadata.version('anndata')` instead.
if Version(anndata.__version__) >= Version("0.11.0rc2"):
/home/figo/software/python_libs/scbiot/.venv/lib/python3.12/site-packages/scanpy/readwrite.py:16: FutureWarning: `__version__` is deprecated, use `importlib.metadata.version('anndata')` instead.
if Version(anndata.__version__) >= Version("0.11.0rc2"):
/home/figo/software/python_libs/scbiot/.venv/lib/python3.12/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
scbiot version 1.1.8
/home/figo/software/python_libs/scbiot/examples
| Package | Version |
|---|---|
| scanpy | 1.11.4 |
| anndata | 0.12.6 |
| cupy-cuda12x | 13.6.0 |
| numpy | 1.26.4 |
| rapids_singlecell | 0.13.5 |
| scbiot | 1.1.8 |
| Component | Info |
| Python | 3.12.8 (main, Jan 14 2025, 22:49:14) [Clang 19.1.6 ] |
| OS | Linux-6.11.0-29-generic-x86_64-with-glibc2.39 |
| CPU | 64 logical CPU cores, x86_64 |
| GPU | ID: 0, NVIDIA RTX 4500 Ada Generation, Driver: 570.86.10, Memory: 24570 MiB |
| Updated | 2026-02-24 04:29 |
Dependencies
| Dependency | Version |
|---|---|
| rmm-cu12 | 25.10.0 (25.10.00) |
| joblib | 1.5.3 |
| natsort | 8.4.0 |
| nvidia-cusolver-cu12 | 11.7.5.82 |
| rapids-dask-dependency | 25.10.0 |
| nvidia-cudnn-cu12 | 9.10.2.21 |
| nvidia-nvshmem-cu12 | 3.4.5 |
| python-dateutil | 2.9.0.post0 |
| pylibraft-cu12 | 25.10.0 (25.10.00) |
| ipython | 9.10.0 |
| ipykernel | 7.2.0 |
| nvidia-nccl-cu12 | 2.27.5 |
| kiwisolver | 1.4.9 |
| nvidia-cusparse-cu12 | 12.5.10.65 |
| cachetools | 7.0.1 |
| matplotlib | 3.10.8 |
| nvidia-cuda-cccl-cu12 | 12.9.27 |
| Deprecated | 1.3.1 |
| pyranges | 0.1.4 |
| debugpy | 1.8.20 |
| cycler | 0.12.1 |
| librmm-cu12 | 25.10.0 (25.10.00) |
| sorted_nearest | 0.0.41 |
| pytz | 2025.2 |
| session-info2 | 0.4 |
| nvidia-cuda-runtime-cu12 | 12.8.90 |
| zarr | 2.18.7 |
| libkvikio-cu12 | 25.10.0 (25.10.00) |
| Pygments | 2.19.2 |
| cuda-core | 0.3.2 (12.9.5) |
| cuvs-cu12 | 25.10.0 (25.10.00) |
| tblib | 3.2.2 |
| pluggy | 1.6.0 |
| scikit-learn | 1.7.2 |
| typing_extensions | 4.15.0 |
| nvidia-curand-cu12 | 10.3.10.19 |
| wrapt | 2.1.1 |
| jupyter_client | 8.8.0 |
| pylibcudf-cu12 | 25.10.0 |
| fastrlock | 0.8.3 |
| cloudpickle | 3.1.2 |
| cuda-pathfinder | 1.3.4 (12.9.5) |
| libcuvs-cu12 | 25.10.0 (25.10.00) |
| traitlets | 5.14.3 |
| comm | 0.2.3 |
| threadpoolctl | 3.6.0 |
| nvidia-nvtx-cu12 | 12.8.90 |
| iniconfig | 2.3.0 |
| Jinja2 | 3.1.6 |
| MarkupSafe | 3.0.3 |
| executing | 2.2.1 |
| tornado | 6.5.4 |
| cuda-bindings | 12.9.5 |
| setuptools | 82.0.0 |
| nvidia-cuda-cupti-cu12 | 12.8.90 |
| libcudf-cu12 | 25.10.0 (25.10.00) |
| ml_dtypes | 0.5.4 |
| cuml-cu12 | 25.10.0 (25.10.00) |
| pillow | 12.1.1 |
| statsmodels | 0.14.6 |
| jaxlib | 0.6.2 |
| pydot | 4.0.1 |
| asttokens | 3.0.1 |
| packaging | 26.0 |
| nvidia-cuda-nvcc-cu12 | 12.9.86 |
| six | 1.17.0 |
| pure_eval | 0.2.3 |
| pytest | 9.0.2 |
| xarray | 2024.11.0 |
| pyzmq | 27.1.0 |
| cudf-cu12 | 25.10.0 (25.10.00) |
| libraft-cu12 | 25.10.0 (25.10.00) |
| treelite | 4.4.1 |
| jedi | 0.19.2 |
| pyparsing | 3.3.2 |
| ncls | 0.0.70 |
| nvidia-nvjitlink-cu12 | 12.8.93 |
| stack-data | 0.6.3 |
| psutil | 7.2.2 |
| tqdm | 4.67.3 |
| patsy | 1.0.2 |
| networkx | 3.6.1 |
| pyarrow | 23.0.0 |
| numcodecs | 0.15.1 |
| filelock | 3.21.0 |
| POT | 0.9.6.post1 |
| libcuml-cu12 | 25.10.0 (25.10.00) |
| texttable | 1.7.0 |
| nvidia-cufft-cu12 | 11.4.1.4 |
| opt_einsum | 3.4.0 |
| parso | 0.8.6 |
| decorator | 5.2.1 |
| legacy-api-wrap | 1.5 |
| platformdirs | 4.6.0 |
| dask | 2025.9.1 |
| nvtx | 0.2.14 |
| scipy | 1.17.0 |
| wcwidth | 0.6.0 |
| jax | 0.6.2 |
| h5py | 3.15.1 |
| jupyter_core | 5.9.1 |
| prompt_toolkit | 3.0.52 |
| llvmlite | 0.44.0 |
| PyYAML | 6.0.3 |
| nvidia-cufile-cu12 | 1.13.1.3 |
| nvidia-cuda-nvrtc-cu12 | 12.9.86 |
| toolz | 1.1.0 |
| docrep | 0.3.2 |
| msgpack | 1.1.2 |
| leidenalg | 0.11.0 |
| sparse | 0.17.0 |
| jax-cuda12-plugin | 0.6.2 |
| jax-cuda12-pjrt | 0.6.2 |
| nx-cugraph-cu12 | 25.10.0 (25.10.00) |
| nvidia-ml-py | 13.590.48 |
| numba | 0.61.2 |
| igraph | 1.0.0 |
| torch | 2.10.0 (2.10.0+cu128) |
| nvidia-cublas-cu12 | 12.9.1.4 |
| pandas | 2.3.3 |
| asciitree | 0.3.3 |
| rapids-logger | 0.1.19 |
Copyable Markdown
| Package | Version | | ----------------- | ------- | | scanpy | 1.11.4 | | anndata | 0.12.6 | | cupy-cuda12x | 13.6.0 | | numpy | 1.26.4 | | rapids_singlecell | 0.13.5 | | scbiot | 1.1.8 | | Dependency | Version | | ------------------------ | --------------------- | | rmm-cu12 | 25.10.0 (25.10.00) | | joblib | 1.5.3 | | natsort | 8.4.0 | | nvidia-cusolver-cu12 | 11.7.5.82 | | rapids-dask-dependency | 25.10.0 | | nvidia-cudnn-cu12 | 9.10.2.21 | | nvidia-nvshmem-cu12 | 3.4.5 | | python-dateutil | 2.9.0.post0 | | pylibraft-cu12 | 25.10.0 (25.10.00) | | ipython | 9.10.0 | | ipykernel | 7.2.0 | | nvidia-nccl-cu12 | 2.27.5 | | kiwisolver | 1.4.9 | | nvidia-cusparse-cu12 | 12.5.10.65 | | cachetools | 7.0.1 | | matplotlib | 3.10.8 | | nvidia-cuda-cccl-cu12 | 12.9.27 | | Deprecated | 1.3.1 | | pyranges | 0.1.4 | | debugpy | 1.8.20 | | cycler | 0.12.1 | | librmm-cu12 | 25.10.0 (25.10.00) | | sorted_nearest | 0.0.41 | | pytz | 2025.2 | | session-info2 | 0.4 | | nvidia-cuda-runtime-cu12 | 12.8.90 | | zarr | 2.18.7 | | libkvikio-cu12 | 25.10.0 (25.10.00) | | Pygments | 2.19.2 | | cuda-core | 0.3.2 (12.9.5) | | cuvs-cu12 | 25.10.0 (25.10.00) | | tblib | 3.2.2 | | pluggy | 1.6.0 | | scikit-learn | 1.7.2 | | typing_extensions | 4.15.0 | | nvidia-curand-cu12 | 10.3.10.19 | | wrapt | 2.1.1 | | jupyter_client | 8.8.0 | | pylibcudf-cu12 | 25.10.0 | | fastrlock | 0.8.3 | | cloudpickle | 3.1.2 | | cuda-pathfinder | 1.3.4 (12.9.5) | | libcuvs-cu12 | 25.10.0 (25.10.00) | | traitlets | 5.14.3 | | comm | 0.2.3 | | threadpoolctl | 3.6.0 | | nvidia-nvtx-cu12 | 12.8.90 | | iniconfig | 2.3.0 | | Jinja2 | 3.1.6 | | MarkupSafe | 3.0.3 | | executing | 2.2.1 | | tornado | 6.5.4 | | cuda-bindings | 12.9.5 | | setuptools | 82.0.0 | | nvidia-cuda-cupti-cu12 | 12.8.90 | | libcudf-cu12 | 25.10.0 (25.10.00) | | ml_dtypes | 0.5.4 | | cuml-cu12 | 25.10.0 (25.10.00) | | pillow | 12.1.1 | | statsmodels | 0.14.6 | | jaxlib | 0.6.2 | | pydot | 4.0.1 | | asttokens | 3.0.1 | | packaging | 26.0 | | nvidia-cuda-nvcc-cu12 | 12.9.86 | | six | 1.17.0 | | pure_eval | 0.2.3 | | pytest | 9.0.2 | | xarray | 2024.11.0 | | pyzmq | 27.1.0 | | cudf-cu12 | 25.10.0 (25.10.00) | | libraft-cu12 | 25.10.0 (25.10.00) | | treelite | 4.4.1 | | jedi | 0.19.2 | | pyparsing | 3.3.2 | | ncls | 0.0.70 | | nvidia-nvjitlink-cu12 | 12.8.93 | | stack-data | 0.6.3 | | psutil | 7.2.2 | | tqdm | 4.67.3 | | patsy | 1.0.2 | | networkx | 3.6.1 | | pyarrow | 23.0.0 | | numcodecs | 0.15.1 | | filelock | 3.21.0 | | POT | 0.9.6.post1 | | libcuml-cu12 | 25.10.0 (25.10.00) | | texttable | 1.7.0 | | nvidia-cufft-cu12 | 11.4.1.4 | | opt_einsum | 3.4.0 | | parso | 0.8.6 | | decorator | 5.2.1 | | legacy-api-wrap | 1.5 | | platformdirs | 4.6.0 | | dask | 2025.9.1 | | nvtx | 0.2.14 | | scipy | 1.17.0 | | wcwidth | 0.6.0 | | jax | 0.6.2 | | h5py | 3.15.1 | | jupyter_core | 5.9.1 | | prompt_toolkit | 3.0.52 | | llvmlite | 0.44.0 | | PyYAML | 6.0.3 | | nvidia-cufile-cu12 | 1.13.1.3 | | nvidia-cuda-nvrtc-cu12 | 12.9.86 | | toolz | 1.1.0 | | docrep | 0.3.2 | | msgpack | 1.1.2 | | leidenalg | 0.11.0 | | sparse | 0.17.0 | | jax-cuda12-plugin | 0.6.2 | | jax-cuda12-pjrt | 0.6.2 | | nx-cugraph-cu12 | 25.10.0 (25.10.00) | | nvidia-ml-py | 13.590.48 | | numba | 0.61.2 | | igraph | 1.0.0 | | torch | 2.10.0 (2.10.0+cu128) | | nvidia-cublas-cu12 | 12.9.1.4 | | pandas | 2.3.3 | | asciitree | 0.3.3 | | rapids-logger | 0.1.19 | | Component | Info | | --------- | --------------------------------------------------------------------------- | | Python | 3.12.8 (main, Jan 14 2025, 22:49:14) [Clang 19.1.6 ] | | OS | Linux-6.11.0-29-generic-x86_64-with-glibc2.39 | | CPU | 64 logical CPU cores, x86_64 | | GPU | ID: 0, NVIDIA RTX 4500 Ada Generation, Driver: 570.86.10, Memory: 24570 MiB | | Updated | 2026-02-24 04:29 |
Load and Prepare Data#
We load the sparse count matrix from an h5ad file using Scanpy. The sparse count matrix will then be placed on the GPU.
data_load_start = time.time()
h5_path = f"{dir}/inputs/1M_neurons_filtered_gene_bc_matrices_h5.h5"
adata = sc.read_10x_h5(
h5_path,
backup_url='https://s3-us-west-2.amazonaws.com/10x.files/samples/cell/1M_neurons/1M_neurons_filtered_gene_bc_matrices_h5.h5',
)
adata.var_names_make_unique()
Configure parameters#
Set marker genes, QC thresholds, and embedding parameters.
# marker genes
MITO_GENE_PREFIX = "mt-" # Prefix for mitochondrial genes to regress out
markers = ["Stmn2", "Hes1", "Olig1"] # Marker genes for visualization
# filtering cells
min_genes_per_cell = 200 # Filter out cells with fewer genes than this expressed
max_genes_per_cell = 6000 # Filter out cells with more genes than this expressed
# filtering genes
min_cells_per_gene = 1 # Filter out genes expressed in fewer cells than this
n_top_genes = 4000 # Number of highly variable genes to retain
# PCA
n_components = 100 # Number of principal components to compute
# KNN
n_neighbors = 15 # Number of nearest neighbors for KNN graph
knn_n_pcs = 50 # Number of principal components to use for finding nearest neighbors
# UMAP
umap_min_dist = 0.3
umap_spread = 1.0
# Gene ranking
ranking_n_top_genes = 50 # Number of differential genes to compute for each cluster
start = time.time()
Verify the shape of the resulting sparse matrix:
adata.shape
(1306127, 27998)
Preprocessing#
preprocess_start = time.time()
Create batch labels#
# Parse suffix after the last '-'
suffix = adata.obs_names.str.rsplit('-', n=1).str[1]
# Store as categorical to save memory
adata.obs["batch"] = suffix.astype("category")
adata.obs["batch"].head()
AAACCTGAGATAGGAG-1 1
AAACCTGAGCGGCTTC-1 1
AAACCTGAGGAATCGC-1 1
AAACCTGAGGACACCA-1 1
AAACCTGAGGCCCGTT-1 1
Name: batch, dtype: category
Categories (133, object): ['1', '10', '100', '101', ..., '96', '97', '98', '99']
Quality Control#
We perform a basic qulitiy control and plot the results
%%time
sc.pp.filter_cells(adata, min_genes=min_genes_per_cell)
sc.pp.filter_cells(adata, max_genes=max_genes_per_cell)
CPU times: user 31.6 s, sys: 13.9 s, total: 45.5 s
Wall time: 45.5 s
%%time
sc.pp.filter_genes(adata, min_cells=min_cells_per_gene)
CPU times: user 16.6 s, sys: 4.82 s, total: 21.4 s
Wall time: 21.4 s
%%time
mito_genes = adata.var_names.str.startswith(MITO_GENE_PREFIX)
n_counts = np.array(adata.X.sum(axis=1))
adata.obs['percent_mito'] = np.array(np.sum(adata[:, mito_genes].X, axis=1)) / n_counts
adata.obs['n_counts'] = n_counts
CPU times: user 3.44 s, sys: 68 μs, total: 3.44 s
Wall time: 3.44 s
%%time
sc.pl.violin(adata, keys="n_genes")
sc.pl.violin(adata, keys="n_counts")
sc.pl.violin(adata, keys="percent_mito")
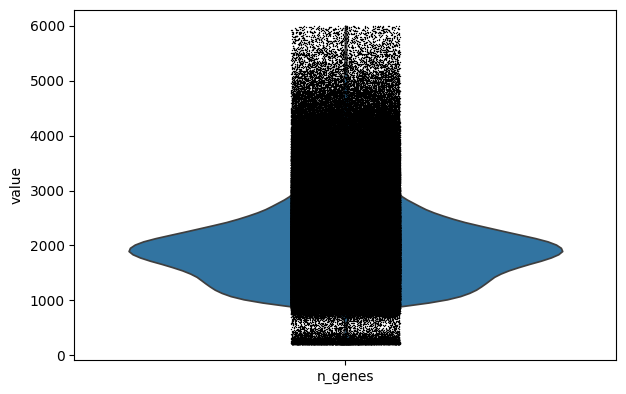
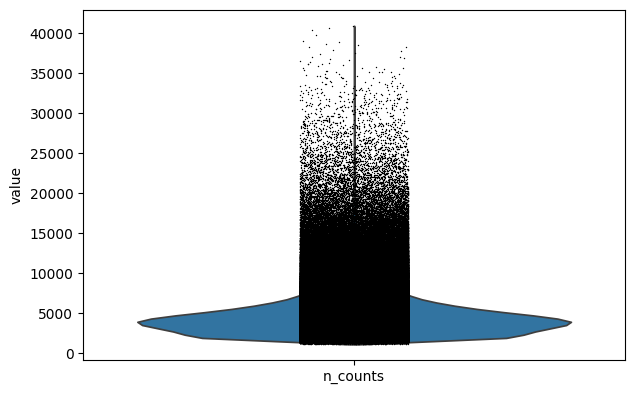
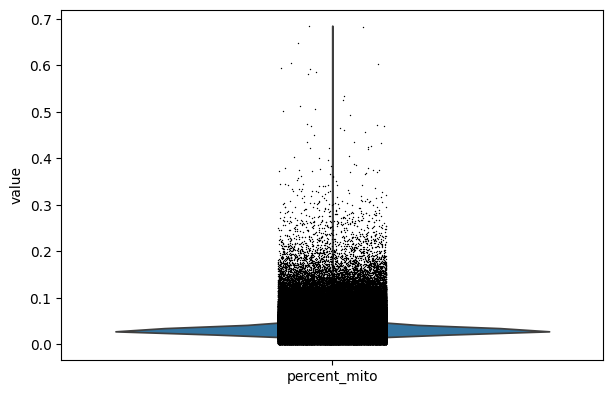
CPU times: user 20.4 s, sys: 9.03 s, total: 29.4 s
Wall time: 9.75 s
Normalize, Scale, and select Most Variable Genes#
%%time
sc.pp.normalize_total(adata, target_sum=1e4)
sc.pp.log1p(adata)
sc.pp.highly_variable_genes(adata, n_top_genes=n_top_genes, flavor = "cell_ranger")
# Retain marker gene expression
for marker in markers:
adata.obs[marker + "_raw"] = adata.X[:, adata.var.index == marker].toarray().ravel()
# Filter matrix to only variable genes
adata = adata[:, adata.var.highly_variable]
CPU times: user 37.4 s, sys: 1.21 s, total: 38.6 s
Wall time: 12.4 s
%%time
gc.collect()
CPU times: user 168 ms, sys: 343 μs, total: 168 ms
Wall time: 167 ms
3051
Regress out confounding factors (number of counts, mitochondrial gene expression)#
%%time
sc.pp.regress_out(adata, ['n_counts', 'percent_mito'])
CPU times: user 48.9 s, sys: 2min 31s, total: 3min 20s
Wall time: 11.9 s
adata.shape
(1291337, 4000)
Scale#
%%time
sc.pp.scale(adata, max_value=10)
CPU times: user 31.4 s, sys: 895 ms, total: 32.3 s
Wall time: 12.9 s
Principal component analysis#
We use PCA to reduce the dimensionality of the matrix to its top 100 principal components.
%%time
sc.tl.pca(adata, n_comps=n_components)
CPU times: user 1h 54min 54s, sys: 17min 20s, total: 2h 12min 15s
Wall time: 2min 48s
We can use scanpy pca_variance_ratio plot to inspect the contribution of single PCs to the total variance in the data.
# sc.pl.pca_variance_ratio(adata, log=True, n_pcs=100)
Run OT#
adata, metrics = scb.ot.integrate(adata,
obsm_key='X_pca',
batch_key='batch',
out_key='X_ot')
print(metrics)
[baseline] KNN backend=FAISS-GPU mix=3.1373 strain=0.00000
[iter 01] mix=3.192 overlap0=0.853 strain=0.00045 floor~0.600 J=0.158 best_it=1
[iter 02] mix=3.201 overlap0=0.786 strain=0.00090 floor~0.607 J=0.190 best_it=2
[iter 03] mix=3.204 overlap0=0.740 strain=0.00315 floor~0.614 J=0.191 best_it=3
[iter 04] mix=3.207 overlap0=0.695 strain=0.01273 floor~0.621 J=0.176 best_it=3
[iter 05] mix=3.207 overlap0=0.694 strain=0.01251 floor~0.629 J=0.175 best_it=3
[iter 06] mix=3.207 overlap0=0.703 strain=0.01279 floor~0.636 J=0.181 best_it=3
[early stop] plateau reached.
[final] it*=3 mix=3.204 overlap0=0.740 strain=0.00315 tw=0.997
[label transfer] skipped; pass label_key to compute alignment metadata
{'mix': 3.20428763122602, 'overlap0': 0.7401466965675354, 'strain': 0.0031453301415237415, 'tw': 0.9965960806681605, 'it': 3}
Export#
Save the OT embedding to disk for reuse.
adata.write(f"{dir}/inputs/brain_1M.h5ad", compression="lzf")
adata = sc.read(f"{dir}/inputs/brain_1M.h5ad")
X_ot = np.asarray(adata.obsm["X_ot"], dtype="float32") # (1291337, 100)
# 2) Build a new AnnData with PCs as X
adata_ot = ad.AnnData(
X=X_ot,
obs=adata.obs.copy(), # keep all metadata (batch, cell_type, etc.)
)
# Give the PCs names, optional but nice
adata_ot.var_names = [f"OT{i+1}" for i in range(X_ot.shape[1])]
adata_ot.obsm["X_ot"] = X_ot
We now load the the AnnData object into VRAM.
Calculate pseudo labels for tracking model performance. Here we begin to use GPU to speed it up#
import rmm
from rmm.allocators.cupy import rmm_cupy_allocator
rmm.reinitialize(
managed_memory=False, # Allows oversubscription
pool_allocator=False, # default is False
devices=0, # GPU device IDs to register. By default registers only GPU 0.
)
cp.cuda.set_allocator(rmm_cupy_allocator)
%%time
rsc.get.anndata_to_GPU(adata_ot)
CPU times: user 30.3 ms, sys: 206 ms, total: 236 ms
Wall time: 234 ms
# 1. Compute neighbors using Harmony-corrected PCA
rsc.pp.neighbors(adata_ot, use_rep='X_ot')
# 2. Run UMAP
rsc.tl.umap(adata_ot)
# 3. Leiden clustering
rsc.tl.leiden(adata_ot, resolution=0.8, key_added='leiden_X_ot')
adata_ot
AnnData object with n_obs × n_vars = 1291337 × 100
obs: 'batch', 'n_genes', 'percent_mito', 'n_counts', 'Stmn2_raw', 'Hes1_raw', 'Olig1_raw', 'leiden_X_ot'
uns: 'neighbors', 'umap', 'leiden_X_ot'
obsm: 'X_ot', 'X_umap'
obsp: 'distances', 'connectivities'
Visualize#
Plot UMAP for the OT embedding to inspect clustering structure.
%%time
sc.pl.umap(
adata_ot,
color=['leiden_X_ot'],
ncols=1
)

CPU times: user 3.06 s, sys: 169 ms, total: 3.22 s
Wall time: 3.05 s