OT on Tahoe-100M dataset via centroid-level integration#
In this notebook, we’ll generate an OT embedding on the Tahoe-100M dataset, which contains cells from various cell lines under different treatments, and then visualize a subset of the data.
Exact optimal transport scales roughly quadratically with the number of cells, so running OT directly on ~100M cells is infeasible.
To make this tractable, we:
Compress each batch into ~2k centroids (MiniBatchKMeans on up to 500k cells per batch).
Run scBIOT’s OT integration only on these centroids.
Learn a displacement field on the centroids and interpolate it back to all 100M cells using FAISS k-NN.
The integrate_centroids call below implements this centroid-level OT + displacement mapping.
Out-of-core Analysis#
For generating PCA embedding: see [here] (https://theislab.github.io/vevo_Tahoe_100m_analysis/vevo_100m_pca.html)
For rapids-singlecell tutorials, see here for scanpy, see here
Setup#
Import dependencies and set GPU/CPU execution flags.
from pathlib import Path
import scbiot as scb
import numpy as np
import dask.distributed as dd
import scanpy as sc
import anndata as ad
import h5py
import dask
from collections import Counter
import pandas as pd
from tqdm import tqdm
import dask
import time
from dask.distributed import Client, LocalCluster
import dask
sc.logging.print_header()
scbiot version 1.1.0
| Package | Version |
|---|---|
| scbiot | 1.1.0 |
| numpy | 2.3.5 |
| dask | 2025.11.0 |
| scanpy | 1.11.5 |
| anndata | 0.12.6 |
| h5py | 3.15.1 |
| pandas | 2.3.3 |
| tqdm | 4.67.1 |
| distributed | 2025.11.0 |
| Component | Info |
| Python | 3.12.12 | packaged by Anaconda, Inc. | (main, Oct 21 2025, 20:16:04) [GCC 11.2.0] |
| OS | Linux-6.11.0-29-generic-x86_64-with-glibc2.39 |
| CPU | 64 logical CPU cores, x86_64 |
| GPU | ID: 0, NVIDIA RTX 4500 Ada Generation, Driver: 570.86.10, Memory: 24570 MiB |
| Updated | 2025-12-02 22:27 |
Dependencies
| Dependency | Version |
|---|---|
| platformdirs | 4.5.0 |
| traitlets | 5.14.3 |
| natsort | 8.4.0 |
| joblib | 1.5.2 |
| ipython | 9.7.0 |
| xarray | 2025.11.0 |
| jax-cuda12-plugin | 0.6.2 |
| defusedxml | 0.7.1 |
| setuptools | 80.9.0 |
| jupyter_client | 8.6.3 |
| numba | 0.62.1 |
| leidenalg | 0.11.0 |
| nvidia-cusolver-cu12 | 11.7.3.90 |
| wcwidth | 0.2.14 |
| debugpy | 1.8.17 |
| jupyter_core | 5.9.1 |
| locket | 1.0.0 |
| nvidia-cufft-cu12 | 11.3.3.83 |
| parso | 0.8.5 |
| nvidia-cublas-cu12 | 12.8.4.1 |
| packaging | 25.0 |
| tblib | 3.2.2 |
| fsspec | 2025.10.0 |
| cloudpickle | 3.1.2 |
| sortedcontainers | 2.4.0 |
| rapids_singlecell | 0.13.4 |
| tornado | 6.5.2 |
| networkx | 3.6 |
| click | 8.3.1 |
| faiss-gpu-cu12 | 1.13.0 |
| Jinja2 | 3.1.6 |
| nvidia-nvjitlink-cu12 | 12.8.93 |
| google-crc32c | 1.7.1 |
| scikit-learn | 1.7.2 |
| cycler | 0.12.1 |
| igraph | 1.0.0 |
| psutil | 7.1.3 |
| pytz | 2025.2 |
| torch | 2.9.1 (2.9.1+cu128) |
| ncls | 0.0.70 |
| six | 1.17.0 |
| session-info2 | 0.2.3 |
| sorted_nearest | 0.0.41 |
| MarkupSafe | 3.0.3 |
| python-dateutil | 2.9.0.post0 |
| nvidia-nvshmem-cu12 | 3.3.20 |
| nvidia-cufile-cu12 | 1.13.1.3 |
| comm | 0.2.3 |
| executing | 2.2.1 |
| threadpoolctl | 3.6.0 |
| zarr | 3.1.5 |
| zict | 3.0.0 |
| pillow | 12.0.0 |
| ml_dtypes | 0.5.4 |
| pyranges | 0.1.4 |
| asttokens | 3.0.1 |
| legacy-api-wrap | 1.5 |
| pyparsing | 3.2.5 |
| filelock | 3.20.0 |
| msgpack | 1.1.2 |
| jedi | 0.19.2 |
| nvidia-cuda-runtime-cu12 | 12.8.90 |
| jaxlib | 0.6.2 |
| matplotlib | 3.10.7 |
| stack-data | 0.6.3 |
| jax | 0.6.2 |
| sparse | 0.17.0 |
| jax-cuda12-pjrt | 0.6.2 |
| pyzmq | 27.1.0 |
| typing_extensions | 4.15.0 |
| numcodecs | 0.16.5 |
| nvidia-cusparse-cu12 | 12.5.8.93 |
| llvmlite | 0.45.1 |
| ipykernel | 7.1.0 |
| nvidia-cuda-nvcc-cu12 | 12.9.86 |
| nvidia-cuda-cupti-cu12 | 12.8.90 |
| toolz | 1.1.0 |
| PyYAML | 6.0.3 |
| nvidia-cuda-nvrtc-cu12 | 12.8.93 |
| nvidia-nccl-cu12 | 2.27.5 |
| charset-normalizer | 3.4.4 |
| pure_eval | 0.2.3 |
| texttable | 1.7.0 |
| prompt_toolkit | 3.0.52 |
| POT | 0.9.6.post1 |
| scipy | 1.16.3 |
| kiwisolver | 1.4.9 |
| Pygments | 2.19.2 |
| nvidia-curand-cu12 | 10.3.9.90 |
| decorator | 5.2.1 |
| nvidia-cudnn-cu12 | 9.10.2.21 |
| donfig | 0.8.1.post1 |
| nvidia-nvtx-cu12 | 12.8.90 |
| opt_einsum | 3.4.0 |
Copyable Markdown
| Package | Version | | ----------- | --------- | | scbiot | 1.1.0 | | numpy | 2.3.5 | | dask | 2025.11.0 | | scanpy | 1.11.5 | | anndata | 0.12.6 | | h5py | 3.15.1 | | pandas | 2.3.3 | | tqdm | 4.67.1 | | distributed | 2025.11.0 | | Dependency | Version | | ------------------------ | ------------------- | | platformdirs | 4.5.0 | | traitlets | 5.14.3 | | natsort | 8.4.0 | | joblib | 1.5.2 | | ipython | 9.7.0 | | xarray | 2025.11.0 | | jax-cuda12-plugin | 0.6.2 | | defusedxml | 0.7.1 | | setuptools | 80.9.0 | | jupyter_client | 8.6.3 | | numba | 0.62.1 | | leidenalg | 0.11.0 | | nvidia-cusolver-cu12 | 11.7.3.90 | | wcwidth | 0.2.14 | | debugpy | 1.8.17 | | jupyter_core | 5.9.1 | | locket | 1.0.0 | | nvidia-cufft-cu12 | 11.3.3.83 | | parso | 0.8.5 | | nvidia-cublas-cu12 | 12.8.4.1 | | packaging | 25.0 | | tblib | 3.2.2 | | fsspec | 2025.10.0 | | cloudpickle | 3.1.2 | | sortedcontainers | 2.4.0 | | rapids_singlecell | 0.13.4 | | tornado | 6.5.2 | | networkx | 3.6 | | click | 8.3.1 | | faiss-gpu-cu12 | 1.13.0 | | Jinja2 | 3.1.6 | | nvidia-nvjitlink-cu12 | 12.8.93 | | google-crc32c | 1.7.1 | | scikit-learn | 1.7.2 | | cycler | 0.12.1 | | igraph | 1.0.0 | | psutil | 7.1.3 | | pytz | 2025.2 | | torch | 2.9.1 (2.9.1+cu128) | | ncls | 0.0.70 | | six | 1.17.0 | | session-info2 | 0.2.3 | | sorted_nearest | 0.0.41 | | MarkupSafe | 3.0.3 | | python-dateutil | 2.9.0.post0 | | nvidia-nvshmem-cu12 | 3.3.20 | | nvidia-cufile-cu12 | 1.13.1.3 | | comm | 0.2.3 | | executing | 2.2.1 | | threadpoolctl | 3.6.0 | | zarr | 3.1.5 | | zict | 3.0.0 | | pillow | 12.0.0 | | ml_dtypes | 0.5.4 | | pyranges | 0.1.4 | | asttokens | 3.0.1 | | legacy-api-wrap | 1.5 | | pyparsing | 3.2.5 | | filelock | 3.20.0 | | msgpack | 1.1.2 | | jedi | 0.19.2 | | nvidia-cuda-runtime-cu12 | 12.8.90 | | jaxlib | 0.6.2 | | matplotlib | 3.10.7 | | stack-data | 0.6.3 | | jax | 0.6.2 | | sparse | 0.17.0 | | jax-cuda12-pjrt | 0.6.2 | | pyzmq | 27.1.0 | | typing_extensions | 4.15.0 | | numcodecs | 0.16.5 | | nvidia-cusparse-cu12 | 12.5.8.93 | | llvmlite | 0.45.1 | | ipykernel | 7.1.0 | | nvidia-cuda-nvcc-cu12 | 12.9.86 | | nvidia-cuda-cupti-cu12 | 12.8.90 | | toolz | 1.1.0 | | PyYAML | 6.0.3 | | nvidia-cuda-nvrtc-cu12 | 12.8.93 | | nvidia-nccl-cu12 | 2.27.5 | | charset-normalizer | 3.4.4 | | pure_eval | 0.2.3 | | texttable | 1.7.0 | | prompt_toolkit | 3.0.52 | | POT | 0.9.6.post1 | | scipy | 1.16.3 | | kiwisolver | 1.4.9 | | Pygments | 2.19.2 | | nvidia-curand-cu12 | 10.3.9.90 | | decorator | 5.2.1 | | nvidia-cudnn-cu12 | 9.10.2.21 | | donfig | 0.8.1.post1 | | nvidia-nvtx-cu12 | 12.8.90 | | opt_einsum | 3.4.0 | | Component | Info | | --------- | --------------------------------------------------------------------------------- | | Python | 3.12.12 | packaged by Anaconda, Inc. | (main, Oct 21 2025, 20:16:04) [GCC 11.2.0] | | OS | Linux-6.11.0-29-generic-x86_64-with-glibc2.39 | | CPU | 64 logical CPU cores, x86_64 | | GPU | ID: 0, NVIDIA RTX 4500 Ada Generation, Driver: 570.86.10, Memory: 24570 MiB | | Updated | 2025-12-02 22:27 |
Technical Notes#
To turn on one or the other of GPU or CPU, use the flag below. If you are using a GPU, configure the gpus flag accordingly to the number of GPUs you have available. Similarly, for the CPU implementation, you can configure the number of workers. We ran this notebook using CPU with a slurm configuration like srun ... -c 32 --mem=300gb, using 16 dask workers and the below sparse chunks size while we were only able to get one GPU, although the beauty of dask is that one is enough to complete the analysis thanks to the out-of-core capabilities. You can of course use fewer CPU cores and this notebook will still be runnable, such is the beauty of truly lazy, chunked computation. Nothing is loaded into memory until it is needed, and only the amount needed to perform the local computation on a chunk of the data.
The interplay between memory and workers is delicate - too many workers and not enough memory will cause your calculation to crash, so often it is good to have a few fewer workers than you think would be best. For example, because a single GPU has somewhere in the range of 32GB, that is more than the individual 16 workers can have who split the 300GB, thereby allowing for a larger chunk size. Furthermore with rapids-memory-management, memory concerns are not so overriding on the GPU.
Caution: Out-of-core support is still quite new in both packages, so we are learning more and more daily about performance optimizations. The information here about performance thus represents our best attempt to provide advice on performance. On only one GPU, preprocessing can be quite lengthy, and therefore it is advisable to use rapids only with more than one GPU (be sure to update the gpus variable accordingly to reflect this - it should be something like '0,1,2,3', for example, for four GPUs). Otherwise, we have observed that the single-GPU PCA is faster than the multi-core PCA (~12.5 min vs. ~18 min), but the time needed to bring the data back to the CPU from the GPU for writing causes the two to be comparable i.e., PCA + writing the results has the same time between one GPU and multi-core CPU with the above specs.
use_gpu = False
# Local-only setup: no HPC / no external Dask cluster
if use_gpu:
import rapids_singlecell as rsc
SPARSE_CHUNK_SIZE = 1_000_000
import rmm
import cupy as cp
from cupyx.scipy import spx
from rmm.allocators.cupy import rmm_cupy_allocator
# Initialize GPU memory on *local* GPU
def set_mem():
rmm.reinitialize(managed_memory=True)
cp.cuda.set_allocator(rmm_cupy_allocator)
import dask.array as da
dask.array.register_chunk_type(spx.csr_matrix)
set_mem()
mod = rsc
else:
# Pure CPU mode on local machine
SPARSE_CHUNK_SIZE = 100_000
mod = sc
Preprocessing#
First, let’s do some standard preprocessing on the datasets. Note that we use ad.experimental.read_elem_as_dask to load the big data, the cell x gene matrix, lazily. The preprocessing is then done lazily i.e., normalization, log1p, and highly variable gene selection. Individually, we’ll do this and then merge all the datasets into one large dataset to be used in the next step. We’ll finally merge the data into one large AnnData for the PCA. Writing this out and then reading it back in is faster than rechunking a virtually concatenated i.e., anndata.concat dataset (dask requires uniform chunks, which would not be possible without rechunking).
# %%time
# adatas = []
# all_highly_variable_genes = []
# for i in tqdm(range(14)):
# id = str(i + 1)
# PATH = f"/c4/scratch/haihui/tahoe100m_h5ad/plate{id}_filt_Vevo_Tahoe100M_WServicesFrom_ParseGigalab.h5ad"
# with h5py.File(PATH, "r") as f:
# # obs / var as before
# adata = ad.AnnData(
# obs=ad.io.read_elem(f["obs"]),
# var=ad.io.read_elem(f["var"]),
# )
# # NEW: use read_elem_lazy instead of read_elem_as_dask
# adata.X = ad.experimental.read_elem_lazy(
# f["X"], chunks=(SPARSE_CHUNK_SIZE, adata.shape[1])
# )
# if use_gpu:
# rsc.get.anndata_to_GPU(adata)
# # 100m filtering
# pass_filter_mask = adata.obs["pass_filter"] == "full"
# adata = adata[pass_filter_mask, :].copy()
# sc.pp.normalize_total(adata)
# sc.pp.log1p(adata)
# sc.pp.highly_variable_genes(adata, n_top_genes=2000)
# highly_variable_genes = set(adata.var_names[adata.var["highly_variable"]])
# all_highly_variable_genes.append(highly_variable_genes)
# adatas.append(adata)
# ## select the genes appears more than two plates
# gene_counts = Counter(gene for genes in all_highly_variable_genes for gene in genes)
# selected_genes = {gene for gene, count in gene_counts.items() if count > 2}
# for i in tqdm(range(14)):
# id = str(i + 1)
# # use the var_names of the i-th plate
# common_genes = list(set(adatas[i].var_names) & selected_genes)
# adata_i = adatas[i][:, common_genes].copy()
# output_path = f"/c4/scratch/haihui/processed/plate{id}_filtered_preprocessed_{'gpu' if use_gpu else 'cpu'}.h5ad"
# adata_i.write_h5ad(output_path)
Merge all data into giant file#
We’ll now merge the data into one large file for the PCA. This is faster than rechunking a virtually concatenated i.e., anndata.concat dataset (dask requires uniform chunks, which would not be possible without rechunking). Furthermore, rechunking can cause a memory blow-up.
# %%time
# data_dict = {}
# for i in range(14):
# data_dict.update({f"plate_{i+1}": f"/c4/scratch/haihui/processed/plate{id}_filtered_preprocessed_{'gpu' if use_gpu else 'cpu'}.h5ad"})
# ad.experimental.concat_on_disk(
# data_dict,
# f'/c4/scratch/haihui/processed/plate_merged_{"gpu" if use_gpu else "cpu"}.h5ad',
# label='plate',
# )
Calculate cell embeddings#
To do this we will use PCA. Both scanpy and rapids_singlecell provide out-of-core implementations of PCA on sparse datasets.
%%time
with h5py.File(f"/home/figo/software/python_libs/plate_merged_{'gpu' if use_gpu else 'cpu'}.h5ad", "r") as f:
adata = ad.AnnData(
obs=ad.io.read_elem(f["obs"]),
var=ad.io.read_elem(f["var"]),
)
adata.X = ad.experimental.read_elem_lazy(
f["X"], chunks=(SPARSE_CHUNK_SIZE, adata.shape[1])
)
CPU times: user 43.9 s, sys: 27.6 s, total: 1min 11s
Wall time: 1min 15s
adata
AnnData object with n_obs × n_vars = 86815078 × 2304
obs: 'sample', 'gene_count', 'tscp_count', 'mread_count', 'drugname_drugconc', 'drug', 'cell_line', 'sublibrary', 'BARCODE', 'pcnt_mito', 'S_score', 'G2M_score', 'phase', 'pass_filter', 'cell_name', 'plate'
%%time
if use_gpu:
rsc.get.anndata_to_GPU(adata)
CPU times: user 2 μs, sys: 0 ns, total: 2 μs
Wall time: 5.72 μs
# %%time
# mod.pp.pca(adata, n_comps=300, mask_var=None)
# if use_gpu:
# adata.obsm["X_pca"] = adata.obsm["X_pca"].map_blocks(
# lambda x: x.get(), meta=np.array([]), dtype=adata.obsm["X_pca"].dtype
# ) # bring back to CPU
# %%time
# adata.obsm["X_pca"].to_zarr(f"/c4/scratch/haihui/processed/plate_merged_pca_{'gpu' if use_gpu else 'cpu'}.zarr")
Export#
Persist PCA/OT embeddings to disk and reload them as needed.
Now the data can be read back in with dask if needed and put into the anndata object. A slight more complex way to write the data, but perhaps more anndata-ic would have been to use write_elem: https://anndata.readthedocs.io/en/latest/generated/anndata.io.write_elem.html
%%time
adata.obsm["X_pca"] = dask.array.from_zarr(f"/home/figo/software/python_libs/plate_merged_pca_{'gpu' if use_gpu else 'cpu'}.zarr")
CPU times: user 3.66 ms, sys: 936 μs, total: 4.6 ms
Wall time: 4.19 ms
Integrate#
Run centroid-level OT on the PCA embedding and store the OT coordinates.
adata, metrics = scb.ot.integrate_centroids(
adata,
obsm_key='X_pca',
batch_key='plate',
out_key='X_ot',
n_centroids_per_batch=2048, # tune: fewer = faster, more = better fidelity
max_samples_per_batch=500_000,
chunk_size=1_000_000,
use_gpu = True,
verbose = True
)
print(metrics)
[baseline] KNN backend=FAISS-GPU mix=2.5756 strain=0.00029
[iter 01] mix=2.574 overlap0=0.939 strain=0.00385 floor~0.600 J=0.155 best_it=1
[iter 02] mix=2.572 overlap0=0.900 strain=0.01116 floor~0.607 J=0.148 best_it=1
[iter 03] mix=2.571 overlap0=0.900 strain=0.01199 floor~0.614 J=0.146 best_it=1
[iter 04] mix=2.571 overlap0=0.906 strain=0.01215 floor~0.621 J=0.150 best_it=1
[early stop] plateau reached.
[final] it*=1 mix=2.574 overlap0=0.939 strain=0.00385 tw=1.000
{'mix': 2.5739512417164883, 'overlap0': 0.938666582107544, 'strain': 0.003846279578283429, 'tw': 0.9997564962314117, 'it': 1, 'n_centroids': 28672}
Visualization#
Briefly, we visualize a subset of the results to avoid meaningless overplotting. However, the full PCA results are still available on disk and are ready for use downstream, whether in deep-learning applications or for simple linear classifiers.
# %%time
# adata.obsm["X_ot"] = dask.array.from_zarr(f"/home/figo/software/python_libs/plate_merged_ot_{'gpu' if use_gpu else 'cpu'}.zarr")
CPU times: user 1.82 ms, sys: 8.41 ms, total: 10.2 ms
Wall time: 23.7 ms
%%time
adata = adata[np.random.randint(0, adata.shape[0], (1_000_000,))]
adata
CPU times: user 767 ms, sys: 4.58 ms, total: 772 ms
Wall time: 803 ms
View of AnnData object with n_obs × n_vars = 1000000 × 2304
obs: 'sample', 'gene_count', 'tscp_count', 'mread_count', 'drugname_drugconc', 'drug', 'cell_line', 'sublibrary', 'BARCODE', 'pcnt_mito', 'S_score', 'G2M_score', 'phase', 'pass_filter', 'cell_name', 'plate'
obsm: 'X_ot'
%%time
mod.pp.neighbors(adata, use_rep='X_ot')
CPU times: user 7min 17s, sys: 5min 36s, total: 12min 53s
Wall time: 7min 30s
%%time
mod.tl.umap(adata)
if use_gpu:
adata.obsm["X_umap"] = adata.obsm["X_umap"].get()
CPU times: user 2h 57min 54s, sys: 20.4 s, total: 2h 58min 14s
Wall time: 8min 22s
%%time
sc.pl.umap(
adata,
color=["cell_line", "plate"],
ncols=1
)
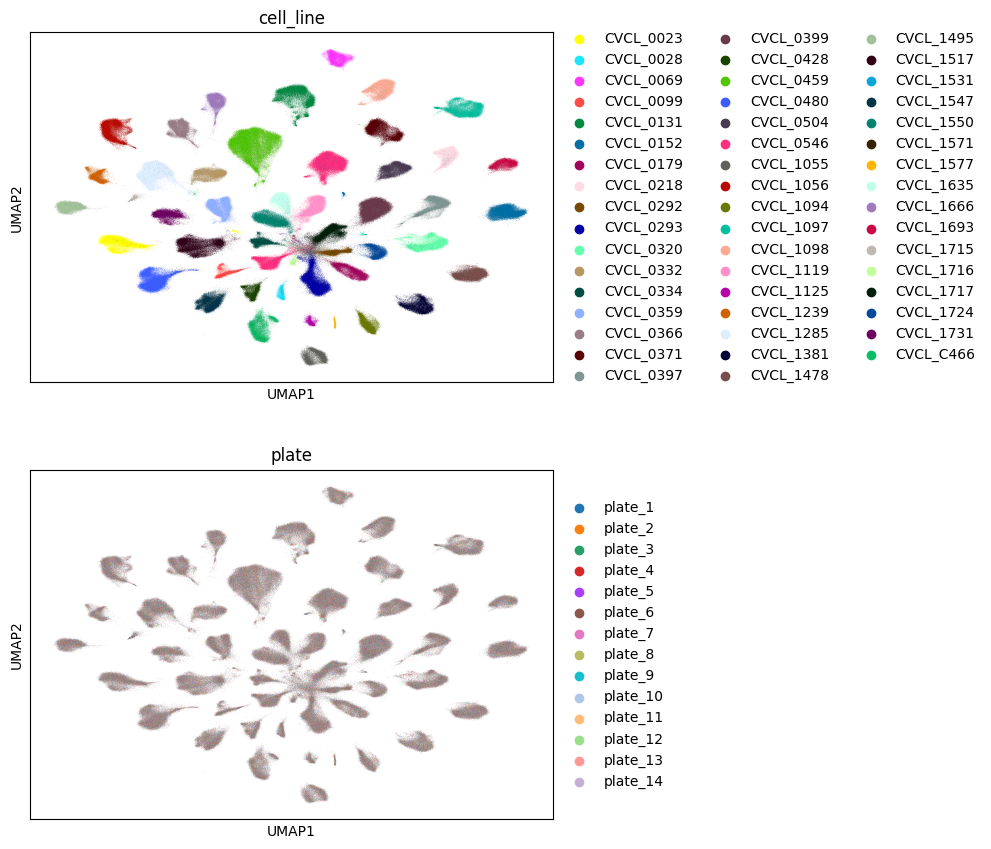
CPU times: user 4.97 s, sys: 7.32 ms, total: 4.97 s
Wall time: 4.97 s
%%time
mod.tl.leiden(
adata,
resolution=0.8,
key_added="leiden")